
The Be operating system file system, known simply as BFS, is the file system for the Haiku, BeOS, and SkyOS operating systems. When it was created in the late '90s as part of the ill-fated BeOS project, BFS's ahead-of-its-time feature set immediately struck the fancy OS geeks. That feature set includes:
- A 64-bit address space
- Use of journaling
- Highly multithreaded reading
- Support of database-like extended file attributes
- Optimization for streaming file access
A dozen years later, the legendary BFS still merits exploration—so we're diving in today, starting with some filesystem basics and moving on to a discussion of the above features. We also chatted with two people intimately familiar with the OS: the person who developed BFS for Be and the developer behind the open-source version of BFS.
A little history
BFS was created in 1997 by Dominic Giampaolo and Cyril Meurillon, both of whom worked at Be. It was designed to be multi-threaded and lightweight, and to support high-volume, streaming multimedia. It was also designed to support the database features of the previous Be file system. Even though it was written at a time when systems typically had only 8MB of RAM and a mere 9GB of disk storage, many of the forward-thinking design decisions made then are still valid today.
BFS didn't quite end when Be shut its doors after failing to get bought by Apple. In 2002, Axel Dörfler re-implemented BFS for Haiku as an open-source project. The last part of this article features an interview with Axel.
Before we can talk about what made BFS so special, we first have to cover some file system basics.
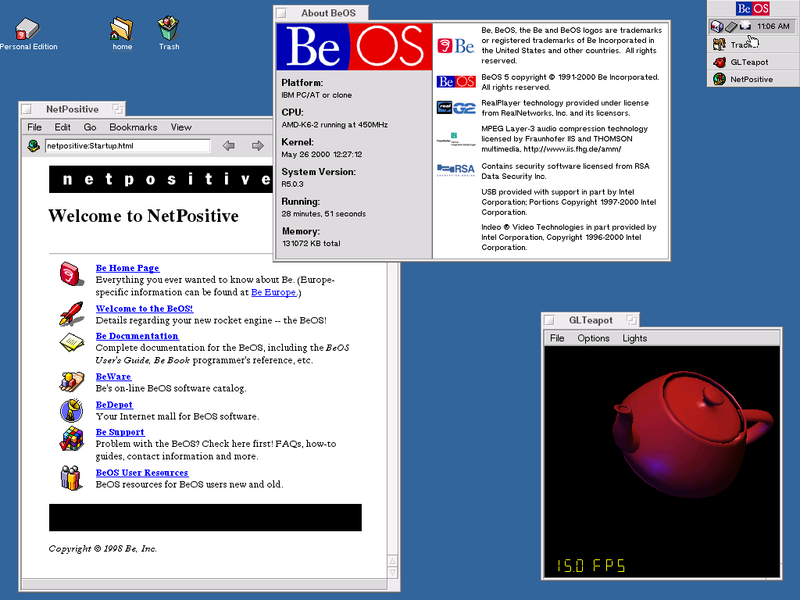
File system basics
At the basic level, a file system exists to manage the data on permanent storage devices. Functions common to most file systems include:
- Creating files and directories
- Opening, reading, writing, deleting, and renaming files
- Reading, writing, and updating file metadata or attributes


 Loading comments...
Loading comments...
